
CSVファイルをエクセルへ読み込みたいのだけど、どうもうまくいかないなー。
いろいろな読み込み方法があるみたいだけど、どれを使えばうまくいくのやら。。
確かに、CSVの読み込み方法ってたくさんあるね。
そうなんですよ。
数字の先頭にゼロが付いていたり、データ内にカンマが含まれていたりするデータがあるのですが、エクセルに読み込んでみるとCSVと同じ状態にならないんです。
エクセルへのCSV読み込みで、よくあることだね。
それに、CSVの文字コードや改行コードによっては、文字化けなども発生するみたいですね。
どんなCSVにも対応できる読み込み方法ってないのでしょうか。
そういう「厄介なCSV」を、何の対策もせずCSVそのままの状態で読み込める方法は、わたしが知る限りではわからないわね。
設定ファイルを準備する必要はあるけど、「ADODB.Recordset」を使った読み込み方法なら、CSVをある程度そのままの状態で読み込めるかも。
ただ、この方法もあらゆる状態のCSVに対応できるかはわからないけどね。
それ、ちょっと試してみたいのですが、どうしたらいいですか?
ということで、CSV読み込みにはいくつかの方法ありますが、扱いが比較的シンプルで、様々なデータ状態のCSVにも概ね対応できる「ADODB.Recordset」を使ってCSVを読み込んでみようと思います。
はじめに
まずはじめに、「CSVの主な読み込み方法」と、CSVそのままの状態でエクセルに読み込めない「厄介なCSV」について触れておきます。
CSVの主な読み込み方法
CSVの読み込み方法ですが、主なもので言うとだいたい以下になるかと思います。
- 「エクセルブック」として読み込む
- 「Openステートメント」で読み込む
- 「FileSystemObject.OpenTextFile」で読み込む
- 「QueryTables」で読み込む
- 「ADODB.Stream」で読み込む
- 「ADODB.Recordset」で読み込む
どれを使っても「カンマ区切りでエクセルに読み込む」だけであれば、基本的には「ほぼ」問題なく読み込めると思いますが、厄介なのが以下のようなデータを持つCSVの場合です。
CSV読み込みにおける厄介な点
- 数字の先頭に「0」がある
→「001」が「1」になってしまう(ゼロ落ち) - 数字の桁数が多い
→「E+」の表示になったり、16桁以降が「0」になったりしてしまう(桁落ち) - 「日付」に自動変換されるデータがある
→「1-1」が「1月1日」となってしまう - データ内に「カンマ( , )」が含まれている
→「”1,500″」が「1と500」の2カラムに分割されてしまう - データ内に「ダブルクォーテーション( ” )」が含まれている
→「”””ABC”””」が「”ABC”」とならず、そのまま読み込まれてしまう - 「セル内改行」がある
→行がずれたり、途中までしか読み込めなかったりする - CSVファイルの「文字コードがUTF-8」
→文字化けしてしまう - CSVファイルの「改行コードがLF」
→全データが1行で読み込まれてしまう
これらの点を回避するために、あれやこれやの対策が必要になりますが、読み込み方法によっては対応できないものもあります。
この記事では「ADODB.Recordset」を使ったCSV読み込みの紹介が目的ですが、他の読み込み方法とどのように違うのかを見るため、いろいろな方法で上記の厄介なCSVを読み込んだ結果も見てみます。
厄介なCSV
読み込むCSVとして、以下のように「厄介な点」を盛り込んだ「厄介なCSV.csv」を作成しました。

いろんな方法で読み込んでみる
「はじめに」で紹介した6つの方法で「厄介なCSV」をエクセルに読み込んで、結果の違いを見てみます。
できるだけCSVそのままの状態で読み込めるように「※一般的な対策」を講じて読み込むものとします。
※セルの書式設定を「文字列」にしたり、文字コードや改行コードの指定ができる場合は、それを指定して読み込んだりする、ということです。厄介な点を回避するために独自の実装はしません。
それでは、読み込んでみましょう。
「エクセルブック」として読み込む
ソースコード
Sub Test()
Const CSV_FILE_PATH As String = "C:\00_myenv\10_macro\01_test\厄介なCSV.csv"
Call ReadCSV_WorkbooksOpen(CSV_FILE_PATH, ThisWorkbook.Worksheets("WorkbooksOpen"))
End Sub
'「エクセルブック」としてCSVを読み込む
Sub ReadCSV_WorkbooksOpen(ByVal csvFilePath As String, ByRef outputWs As Worksheet)
With Workbooks.Open(Filename:=csvFilePath)
.Worksheets(1).Cells(1, 1).CurrentRegion.Copy outputWs.Cells(1, 1)
.Close
End With
End Sub実行結果

回避状況
| 読み込み方法 | ゼロ落ち | 桁落ち | 日付 自動変換 | カンマ | ダブル クォーテーション | セル内改行 | UTF-8 | LF |
| エクセルブック | NG | NG | NG | OK | OK | OK | NG | OK |
エクセル特有のデータ自動変換はされてしまいます。
データ内にカンマやダブルクォーテーションが含まれる場合には対応できています。(エクセルブックとして読み込む際に、CSVであると認識されるため?)
文字化けしていて分かりづらいですが、セル内改行も対応できているようです。(別途、CSVの文字コードをShift-JISにして読み込んでみましたが、セル内改行に対応できていました)
また、文字コードの指定はできないようです。
「Openステートメント」で読み込む
ソースコード
Sub Test()
Const CSV_FILE_PATH As String = "C:\00_myenv\10_macro\01_test\厄介なCSV.csv"
Call ReadCSV_OpenStatement(CSV_FILE_PATH, ThisWorkbook.Worksheets("OpenStatement"))
End Sub
'「Openステートメント」でCSVを読み込む
Sub ReadCSV_OpenStatement(ByVal csvFilePath As String, ByRef outputWs As Worksheet)
Open csvFilePath For Input As #1
Dim i As Long: i = 1
Do Until EOF(1)
Dim oneLine As String
Line Input #1, oneLine '1行読み込み
Dim oneLineArr() As String
oneLineArr = Split(oneLine, ",") 'カンマ区切りで配列に格納
Dim j As Long
For j = 0 To UBound(oneLineArr)
outputWs.Cells(i, j + 1).NumberFormat = "@" 'セルの書式を「文字列」に設定
outputWs.Cells(i, j + 1).Value = oneLineArr(j)
Next j
i = i + 1
Loop
Close #1
End Sub実行結果

※結果が横に長いため、右側は見切れています。
回避状況
| 読み込み方法 | ゼロ落ち | 桁落ち | 日付 自動変換 | カンマ | ダブル クォーテーション | セル内改行 | UTF-8 | LF |
| Openステートメント | OK | OK | OK | NG | NG | OK | NG | NG |
エクセルに値を設定する前に、セルの書式を「文字列」に設定することで、エクセル特有のデータ自動変換は回避できています。
カンマですが、「Split」でカンマ区切りに分割しているだけなので、データ内にカンマを含む場合は、当然のごとく、データ自体が分割されてしまいます。
ダブルクォーテーションに対しては何の対策もしていないので、そのまま表示されてしまいます。
これらを回避するには、頑張って独自の実装をするか、正規表現を用いて実装するか、くらいしか思いつきませんが、いずれにしてもあらゆるパターンを網羅し、間違いなく解析できるようにするのは、なかなか難しいのではないでしょうか。
文字コードの指定はできないようです。
改行コードについては、「Line Input」が「CR、またはCRLFがあるまでを1行と判断する」らしいので、CSV全体が1行として読み込まれてしまいます。

回避するには「LFを区切り文字としてSplitで1行ごとに分割する」といった実装が必要になります。
「FileSystemObject.OpenTextFile」で読み込む
ソースコード
Sub Test()
Const CSV_FILE_PATH As String = "C:\00_myenv\10_macro\01_test\厄介なCSV.csv"
Call ReadCSV_FileSystemObject(CSV_FILE_PATH, ThisWorkbook.Worksheets("FileSystemObject"))
End Sub
'「FileSystemObject.OpenTextFile」でCSVを読み込む
Sub ReadCSV_FileSystemObject(ByVal csvFilePath As String, ByRef outputWs As Worksheet)
With CreateObject("Scripting.FileSystemObject").OpenTextFile(csvFilePath, 1)
Dim i As Long: i = 1
Do While .AtEndOfStream = False
Dim oneLineArr() As String
oneLineArr = Split(.ReadLine, ",") '1行読み込み、カンマ区切りで配列に格納
Dim j As Long
For j = 0 To UBound(oneLineArr)
outputWs.Cells(i, j + 1).NumberFormat = "@" 'セルの書式を「文字列」に設定
outputWs.Cells(i, j + 1).Value = oneLineArr(j)
Next j
i = i + 1
Loop
.Close
End With
End Sub実行結果

回避状況
| 読み込み方法 | ゼロ落ち | 桁落ち | 日付 自動変換 | カンマ | ダブル クォーテーション | セル内改行 | UTF-8 | LF |
| FileSystemObject | OK | OK | OK | NG | NG | NG | NG | OK |
エクセルのデータ自動変換、カンマ、ダブルクォーテーション、文字コードについては、一つ上の「Openステートメント」と同じ理由で、同様の結果となります。
改行コードについてですが、「ReadLine」は「改行文字の前までを1行と判断する」らしいので、「LF」にも対応できているようです。
ただ、これが理由でセル内改行の「LF」も行末の改行と判定されてしまっています。
「QueryTables」で読み込む
ソースコード
Sub Test()
Const CSV_FILE_PATH As String = "C:\00_myenv\10_macro\01_test\厄介なCSV.csv"
Call ReadCsv_QueryTables(CSV_FILE_PATH, ThisWorkbook.Worksheets("QueryTables"))
End Sub
Sub ReadCsv_QueryTables(ByVal csvFilePath As String, ByRef outputWs As Worksheet)
With outputWs.QueryTables.Add(Connection:="Text;" & csvFilePath, Destination:=outputWs.Range("A1"))
.AdjustColumnWidth = False
.TextFileColumnDataTypes = Array(2, 2, 2, 2, 2, 2, 2) '各カラムの型に「文字列(2)」を指定
.TextFilePlatform = 65001 '文字コードに「UTF-8(65001)」を指定
.TextFileCommaDelimiter = True
.RefreshStyle = xlOverwriteCells
.Refresh BackgroundQuery:=False
.Delete
End With
End Sub実行結果

回避状況
| 読み込み方法 | ゼロ落ち | 桁落ち | 日付 自動変換 | カンマ | ダブル クォーテーション | セル内改行 | UTF-8 | LF |
| QueryTables | OK | OK | OK | OK | OK | NG | OK | OK |
「TextFileColumnDataTypes」プロパティで、各カラムの型を「文字列」に設定することで、エクセルの自動変換を回避できています。
カンマやダブルクォーテーションも対応できています。
セル内改行には対応できないようで、セル内改行の後続が切れてしまいました。
文字コードは指定ができるため、UTF-8でも文字化けしていません。
改行コード「LF」も対応できています。
「ADODB.Stream」で読み込む
ソースコード
Sub Test()
Const CSV_FILE_PATH As String = "C:\00_myenv\10_macro\01_test\厄介なCSV.csv"
Call ReadCsv_ADODBStream(CSV_FILE_PATH, ThisWorkbook.Worksheets("ADODBStream"))
End Sub
Sub ReadCsv_ADODBStream(ByVal csvFilePath As String, ByRef outputWs As Worksheet)
With CreateObject("ADODB.Stream")
.charSet = "UTF-8" '文字コードに「UTF-8」を指定
.LineSeparator = 10 '改行コードに「LF」を指定
.Open
.LoadFromFile csvFilePath
Dim i As Long: i = 1
Do Until .EOS
Dim oneLineArr As Variant
oneLineArr = Split(.ReadText(-2), ",") '1行読み込み、カンマ区切りで配列に格納
Dim j As Long
For j = 0 To UBound(oneLineArr)
outputWs.Cells(i, j + 1).NumberFormat = "@" 'セルの書式を「文字列」に設定
outputWs.Cells(i, j + 1).Value = oneLineArr(j)
Next j
i = i + 1
Loop
.Close
End With
End Sub実行結果
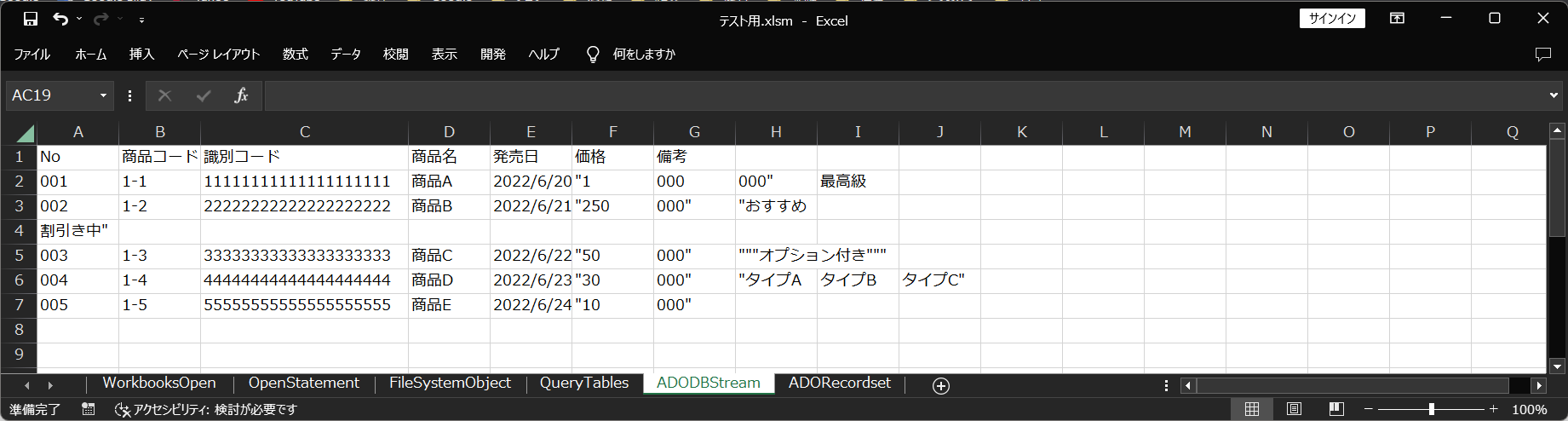
回避状況
| 読み込み方法 | ゼロ落ち | 桁落ち | 日付 自動変換 | カンマ | ダブル クォーテーション | セル内改行 | UTF-8 | LF |
| ADODB.Stream | OK | OK | OK | NG | NG | NG | OK | OK |
エクセルのデータ自動変換、カンマ、ダブルクォーテーションについては、「Openステートメント」と同じ理由で、同様の結果となります。
文字コードと改行コードは指定できるので、対応できています。
セル内改行は行末の改行として判定されています。
「ADODB.Recordset」で読み込む(本記事の目的)
ソースコード
Sub Test()
Const CSV_FILE_PATH As String = "C:\00_myenv\10_macro\01_test\厄介なCSV.csv"
Call ReadCSV_ADODBRecordset(CSV_FILE_PATH, ThisWorkbook.Worksheets("ADORecordset"))
End Sub
Sub ReadCSV_ADODBRecordset(ByVal csvFilePath As String, ByRef outputWs As Worksheet)
'CSVのファイル名を取得
Dim csvFileName As String
csvFileName = CreateObject("Scripting.FileSystemObject").GetFileName(csvFilePath)
'CSVのフォルダパスを取得
Dim csvFolderPath As String
csvFolderPath = CreateObject("Scripting.FileSystemObject").GetParentFolderName(csvFilePath)
'SQL文の準備
'FROM句は、CSVのファイル名を"[]"で括る
Dim sql As String
sql = ""
sql = sql & "SELECT * "
sql = sql & "FROM [" & csvFileName & "]"
'CSVへのConnectionを生成
Dim adoCon As Object
Set adoCon = CreateObject("ADODB.Connection")
With adoCon
.Provider = "Microsoft.ACE.OLEDB.12.0"
.Properties("Extended Properties").Value = "Text"
.Properties("Data Source").Value = csvFolderPath 'CSVのフォルダパスを指定
.Open
End With
'Recordsetを生成し、SQLを実行
Dim adoRs As Object
Set adoRs = CreateObject("ADODB.Recordset")
adoRs.Open sql, adoCon
'ヘッダー部の出力
Dim i As Long: i = 1
Dim field As Variant
For Each field In adoRs.Fields
outputWs.Cells(1, i) = field.Name
i = i + 1
Next field
'データ部の出力
outputWs.Range("A2").CopyFromRecordset adoRs
outputWs.Range("A1").CurrentRegion.NumberFormat = "@" 'セルの書式を「文字列」に設定
adoCon.Close
Set adoRs = Nothing
Set adoCon = Nothing
End Sub「ADODB.Recordset」では、設定ファイル「schema.ini」を準備することで、CSVの属性を指定することができます。
準備しない場合はデフォルト設定で読み込まれるため、エクセル自動変換や文字化けなどが発生する可能性があります。
「schema.ini」ファイルの作成
;CSVファイル名の指定。[]で括る。
[厄介なCSV.csv]
;区切り文字の指定
;CSVDelimited:カンマ区切り
;TabDelimited:タブ区切り
Format=CSVDelimited
;ファイルの文字コードの指定
;UTF-8:65001
;SJIS:932
;EUCJP:51932
CharacterSet=65001
;CSVのヘッダー部有無の指定
ColNameHeader=True
;以降、CSVのカラム名と読み込み時のデータ型を指定
;今回は全てテキストとする
Col1=No Text
Col2=商品コード Text
Col3=識別コード Text
Col4=商品名 Text
Col5=発売日 Text
Col6=価格 Text
Col7=備考 Text
設定の意味は上記のコメントの通りで、読み込むCSVに設定を合わせて作成します。(他にも指定できることはありますが、ここでは割愛します)
また、作成時には、以下の点に注意してください。
- ファイルの文字コードは「SJIS」にしてください。他の文字コードだと、うまく読み込めなくなります。
- ファイル名は「schema.ini」固定です。マクロ実行時にこのファイル名のファイルが自動で読み込まれます。ファイル名が違うと、読み込まれません。
- 以下のように、配置する場所は、CSVと同じフォルダ内です。
実行結果
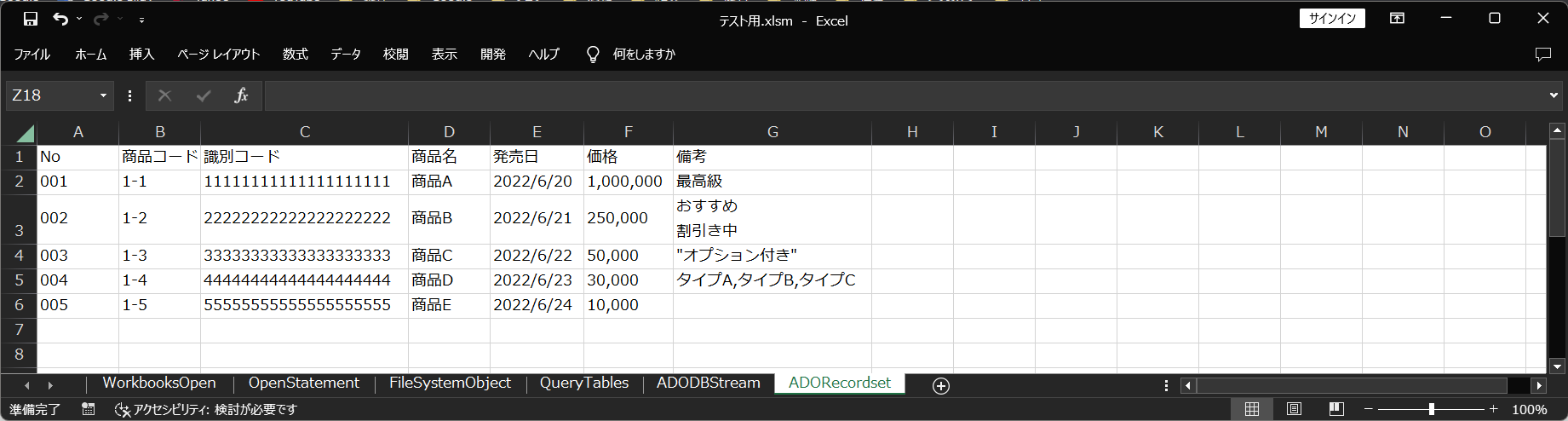
回避状況
| 読み込み方法 | ゼロ落ち | 桁落ち | 日付 自動変換 | カンマ | ダブル クォーテーション | セル内改行 | UTF-8 | LF |
| ADODB.Recordset | OK | OK | OK | OK | OK | OK | OK | OK |
今回準備したCSVでは厄介な点を全て回避できています。
説明
以上、6つの方法で今回準備した「厄介なCSV」を読み込んでみましたが、「ADODB.Recordset」のみが全ての厄介な点を回避できました。
ここで、「ADODB.Recordset」を使うメリット、デメリット、注意点を挙げておきます。
メリット
- 「schema.ini」という設定ファイルで、区切り文字や文字コード、カラムのデータ型などの指定が可能。
- そのため、読み込むCSVが変わっても、実装の変更が不要。
- 自分で回避策の実装をする必要がないので、バグが発生しづらい。
- 読み込み速度が高速である。
- 今回の記事で試した「厄介な点」はすべて回避できる。
デメリット
- 「schema.ini」を用意しなければならないという手間がある。
- 「schema.ini」の内容は、「CSVごとにファイル名を書いて設定を書く」ので、たくさんのCSVファイルを読み込む場合には、ファイルごとに設定を書かねばならないので不向き。
注意点
- 扱えるカラム数は「255個まで」。超えた分は無視されるか、(schema.iniを使う場合のみ?)実行時エラーとなる。
- 1カラムの文字数は「255文字まで」。超えた分は切れる。
- カラム名に同名がある場合、区別できるような名前に自動変換されてしまう。
ちなみに、「schema.ini」でカラムの型を「TEXT」にしているにもかかわらず、改めてソースコード48行目でセルの書式設定を「文字列」にしているのは、エクセルに読み込んでもセルの書式が「標準」のままなので、ダブルクリックなどするとエクセルの自動変換がされてしまうため、改めて書式を「文字列」にしています。
また、「schema.ini」には、以下のように複数ファイルに対して設定を記載できます。
[サンプル1.csv]
Format=CSVDelimited
CharacterSet=65001
ColNameHeader=True
Col1=XXX Text
Col2=XXX Text
Col3=XXX Text
[サンプル2.csv]
Format=CSVDelimited
CharacterSet=65001
ColNameHeader=True
Col1=XXX Text
Col2=XXX Text
Col3=XXX Text
・
・
・ですので、デメリットにはたくさんのファイル読み込みには不向きと書きましたが、数ファイルくらいであれば、それほど手間ではないかもしれません。
たくさんのファイルで「ADODB.Recordset」を使うのであれば、「schema.ini」を読み込むCSVに合わせて自動生成するようなプログラムを別途作成するなどの工夫が必要かと思います。
もしよろしければ、テキストファイル出力の記事も参考にしてみてください。

まとめ
この記事では「厄介なCSV」をそのままの状態でエクセルに読み込む方法として「ADODB.Recordset」を紹介しました。
「厄介なCSV」に出会うことがあったら参考にしてみてください。
ですが、CSVに厄介な点が含まれないのであれば、他の方法で読み込んでもなんら問題はありません。
「ADODB.Recordset」は、設定ファイルの準備が必要ですし、たくさんのCSVを読み込む場合には不向きでもあるので、CSVに応じた方法を選択することをお勧めします。
また、CSVにデータ内カンマやセル内改行などの「厄介な点」を含まないように事前に取り決めておくことで、読み込み結果が変になることの回避もできるのではないかと思います。
以上、ご覧いただきありがとうございました。